时间复杂度为O(nlogn)的排序
排序(一)中讲了冒泡排序,插入排序,选择排序。其中插入排序比冒泡排序更常使用的原因是,插入排序只有1次赋值操作,而冒泡排序有3次。它们3种排序的时间复杂度都是O(n²)。接下来会介绍两种时间复杂度为O(nlogn)的排序算法,即归并排序和快速排序。因为时间复杂度的关系,这两种排序算法被广泛用于大规模的数据排序。
归并排序(Merge Sort)
归并排序就是将一个无序数组从中间分成前后两个部分,然后对这两个部分分别进行排序,再将排序好的两个部分合并在一起,这样整个数组就排序完了。下面是排序的过程:

归并排序使用了分治的思想,即分而治之。归并排序使用了递归的代码,要想写出递归,首先先要分析递归的公式,然后找到终止条件。
// 递归公式
merge_sort(p...r) = merge(merge_sort(p...q), merge_sort(q+1...r))
// 终止条件
p >= r 不用再继续分解
解释一下上面的公式,就是假设将p到r的数组进行排序,找到中间值q,分别排序p到q,q+1到r,然后再将结果合并在一起。转换成伪代码如下所示:
// 归并算法,A是需要排序的数组,n表示数组大小
merge_sort(A, n) {
merge_sort_c(A, 0, n-1)
}
// 递归调用
merge_sort_c(A, p, r) {
// 递归终止条件
if p >= r { return }
// 取p到r的中间位置q
q = (p+r)/2
// 分治递归
merge_sort_c(A, p, q)
merge_sort_c(A, q+1, r)
// 将结果合并
merge(A[p...r], A[p...q], A[q+1...r])
}
我们如何将A[p…q]和A[q+1…r]合并呢?
我们申请一个临时数组 tmp,大小与 A[p…r]相同。我们用两个游标 i 和 j,分别指向 A[p…q]和 A[q+1…r]的第一个元素。比较这两个元素 A[i]和 A[j],如果 A[i]<=A[j],我们就把 A[i]放入到临时数组 tmp,并且 i 后移一位,否则将 A[j]放入到数组 tmp,j 后移一位。继续上述比较过程,直到其中一个子数组中的所有数据都放入临时数组中,再把另一个数组中的数据依次加入到临时数组的末尾,这个时候,临时数组中存储的就是两个子数组合并之后的结果了。最后再把临时数组 tmp 中的数据拷贝到原数组 A[p…r]中。过程如图所示:

转换成伪代码如下:
merge(A[p...r], A[p...q], A[q+1...r]) {
var i := p, j := q+1, k := 0 // 初始化变量i,j,k
var tmp := new array[0...r-p] // 申请一个与A[p...r]一样大的数组
while i <= q && j <=r do {
if A[i] <= A[j] {
tmp[k++] = A[i++]
} else {
tmp[k++] = A[j++]
}
}
// 判断哪个子数组当中有剩余的数据
var start := i, end := q
if j <= r {
start := j
end := r
}
// 将剩余的数据拷贝到tmp
while start <= end do {
tmp[k++] = A[start++]
}
// 将tmp拷贝回A[p...r]中
for i:=0; i <= r-p; i ++ {
a[p+i] = tmp[i]
}
}
归并排序的时间复杂度为什么是O(nlogn)?
假设我们对n个元素进行归并排序的时间为T(n),那么分成两个子数组就是T(n/2),merge合并也为n,所以可以写成:
T(1) = C // n=1时为常量
T(n) = 2*T(n/2) + n; n > 1
分解一下就是:
T(n) = 2*T(n/2) + n
= 2*(2*T(n/4) + n/2) + n = 4*T(n/4) + 2*n
= 4*(2*T(n/8) + n/4) + 2*n = 8*T(n/8) + 3*n
= 8*(2*T(n/16) + n/8) + 3*n = 16*T(n/16) + 4*n
......
= 2^k * T(n/2^k) + k * n
T(1) = T(n/2^k)
n/2^k = 1
k = log2n
// 将k代入上面的公式
T(n) = Cn + nlog2n
// 用大O标记法
T(n) = nlogn
归并排序之所以没有快速排序应用广泛,是因为归并排序不是原地排序。它所使用了一个tmp空间存储数据。
归并排序的golang实现:
package main
import "fmt"
// 合并 [l,r] 两部分数据,mid 左半部分的终点,mid + 1 是右半部分的起点
func merge(arr []int, l int, mid int, r int) {
// 因为需要直接修改 arr 数据,这里首先复制 [l,r] 的数据到新的数组中,用于赋值操作
temp := make([]int, r-l+1)
for i := l; i <= r; i++ {
temp[i-l] = arr[i]
}
// 指向两部分起点
left := l
right := mid + 1
for i := l; i <= r; i++ {
// 左边的点超过中点,说明只剩右边的数据
if left > mid {
arr[i] = temp[right-l]
right++
// 右边的数据超过终点,说明只剩左边的数据
} else if right > r {
arr[i] = temp[left-l]
left++
// 左边的数据大于右边的数据,选小的数字
} else if temp[left - l] > temp[right - l] {
arr[i] = temp[right - l]
right++
} else {
arr[i] = temp[left - l]
left++
}
}
}
func MergeSort(arr []int, l int, r int) {
if l >= r {
return
}
// 递归向下
mid := (r + l) / 2
MergeSort(arr, l, mid)
MergeSort(arr, mid+1, r)
// 归并向上
merge(arr, l, mid, r)
}
func main() {
arr := []int{3, 1, 2, 5, 6, 43, 4}
MergeSort(arr, 0, len(arr)-1)
fmt.Println(arr)
}
快速排序(Quick Sort)
乍一看起来,快排和归并是很像的。假如我们还是排序A[p…r],我们选择p到r之间的任意一个数为分区点(pivot)。遍历p到r的数据将小于pivot的数放在pivot左边,大于pivot的数放在pivot右边,将pivot放在中间,这样数组p到r就被分成了3部分。即p到q-1小于pivot, 中间是pivot, 右边是q到r大于pivot。
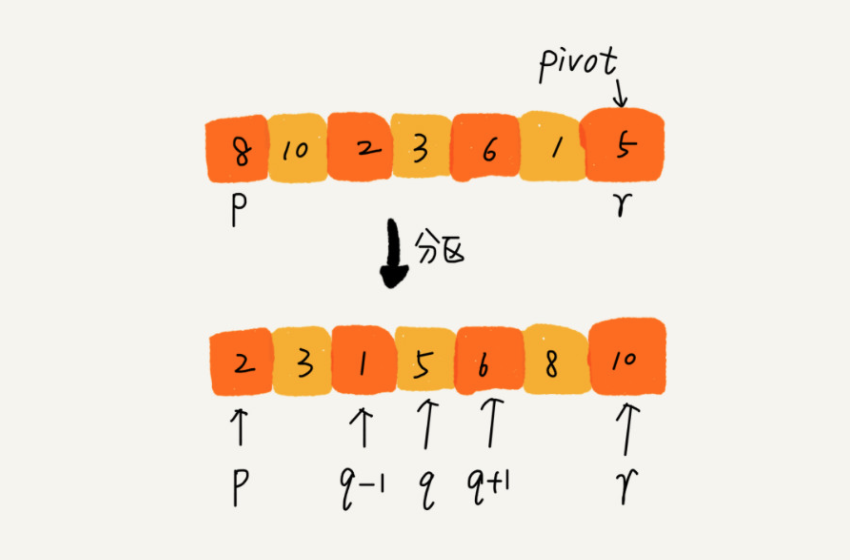
同样,我们使用递归对左右两边进行排序,直到区间缩小为1,就说明排序完成。递归公式如下:
// 递归公式
quick_sort(p...r) = quick_sort(p...q-1) + quick_sort(q...r)
//终止条件
p >= r
换成伪代码就是:
// 快速排序,A是数组,n是数组大小
quick_sort(A, n) {
quick_sort_c(A, 0, n-1)
}
quick_sort(A, p, r) {
if p >= r { return }
q = partition(A, p, r) // 获得pivot(一般情况下,可以获得p到r之间的最后一个元素)
quick_sort_c(A, p, q-1)
quick_sort_c(A, q, r)
}
我们申请两个临时数组 X 和 Y,遍历 A[p…r],将小于 pivot 的元素都拷贝到临时数组 X,将大于 pivot 的元素都拷贝到临时数组 Y,最后再将数组 X 和数组 Y 中数据顺序拷贝到 A[p…r]。

但是这样和归并一样,申请了新的空间去存储数据,并不是原地排序算法,如果要使partition函数不能占用额外的空间,我们就要这样:
partition(A, p ,r) {
pivot := A[r]
i := p
for j := p; j <= r-1; j ++ {
if A[j] < pivot {
swap(A[i], A[j])
i := i+1
}
}
swap(A[i], A[r])
retuen i
}
这里的处理有点类似选择排序。我们通过游标 i 把 A[p…r-1]分成两部分。A[p…i-1]的元素都是小于 pivot 的,我们暂且叫它“已处理区间”,A[i…r-1]是“未处理区间”。我们每次都从未处理的区间 A[i…r-1]中取一个元素 A[j],与 pivot 对比,如果小于 pivot,则将其加入到已处理区间的尾部,也就是 A[i]的位置。
下面是整个过程:

快速排序的golang实现如下:
package main
import "fmt"
func quickSort(source []int, l, u int) {
if l < u {
m := partition(source, l, u)
quickSort(source, l, m-1)
quickSort(source, m, u)
}
}
func partition(source []int, l, u int) int { //划分
var (
pivot = source[l]
left = l
right = l+1
)
for ;right<u; right++ {
if source[right] <= pivot {
left++
source[left], source[right] = source[right], source[left]
}
}
source[l], source[left] = source[left], source[l]
return left+1
}
func main() {
s := []int{10, 6, 7, 4, 2, 5}
quickSort(s, 0, len(s))
fmt.Println(s)
}
可以发现,归并排序的处理过程是由下到上的,先处理子问题,然后再合并。而快排正好相反,它的处理过程是由上到下的,先分区,然后再处理子问题。归并排序虽然是稳定的、时间复杂度为 O(nlogn) 的排序算法,但是它是非原地排序算法。我们前面讲过,归并之所以是非原地排序算法,主要原因是合并函数无法在原地执行。快速排序通过设计巧妙的原地分区函数,可以实现原地排序,解决了归并排序占用太多内存的问题。